前言
最近 QQ 好像更新了个成语接龙红包,以及出现了“一个顶俩”这种成语接龙终结者。于是想到可以基于 ArangoDB 的图来做成语接龙实验,达到最短路径接龙到“一个顶俩”,或者任意长度的接龙。
实验过程
首先当然是要爬成语,来源其实有很多,不过这不重要,已经从友人A 那里拿到了一份新鲜出炉的大约 29000 条成语的数据,包括了首尾字的拼音。当然也包括了手动添加的“一个顶俩”。

插入成语到数据库里
在拿到这些成语之后,首先得把这些都先存到数据库中
def import_chengyu():
file = open("chengyu2.json", "r")
chengyu = json.load(file)
coll = chengyu_db.collection("chengyu")
chengyu_regular = []
for cy in chengyu:
chengyu_regular.append({
"word": cy["word"],
"first": cy["pinyin_first"],
"last": cy["pinyin_last"]
})
coll.insert_many(chengyu_regular)
因为给的json里面的拼音的 key 有个 pinyin 前缀,于是打算先去掉,然后再批量插入进去。
构建图的边
刚刚已经把成语作为节点插入到数据库里面,下一步是最重要的一步,就是计算边。
边的计算很简单,思路上是先整理成一个 map<string, list<obj>> 这种,key 就是首字拼音,value 则是一个数组,存放所有以 key 开头的成语。
chengyu_cur = chengyu_db.aql.execute("FOR c IN chengyu RETURN c")
chengyu = []
chengyu_map = {}
for cy in tqdm(chengyu_cur, unit_scale=True):
first = cy["first"]
chengyu.append(cy)
if chengyu_map.get(first):
chengyu_map[first].append(cy)
else:
chengyu_map[first] = [cy]
这里用了个进度条的库,tqdm。
首选得从数据库里面把之前插入的取回来,因为要拿到文档的 id 和 key,才能构建一条边。不过实际上是可以在插入的时候就设置 return new 来直接返回的,因为是分了步骤执行的脚本,所以就单独取回也没什么关系。
这个 execute 取回来的是一个 cursor,虽然可以直接遍历,但是因为后面构建边的时候还需要遍历一边成语,而游标又只能单向遍历一次,所以只能再用一个 chengyu 数组存一下每个成语了。不过后来仔细思考了下其实也可以不用存,只不过构建边的时候多加一层 for 循环。
然后就是构建边了,这个其实也简单。
edges = []
for cy in tqdm(chengyu, unit_scale=True):
last = cy["last"]
nexts = chengyu_map.get(last)
if not nexts:
continue
for n in nexts:
edges.append({
"_from": "chengyu/{}".format(cy["_key"]),
"_to": "chengyu/{}".format(n["_key"])
})
大概会生成 520多万条边,会占用掉约2GB的内存空间。这里其实原本是打算外层循环每一次就提交一批边的,这样就不需要那么多内存了,但实际遇到了一个令人头疼的问题。
一开始还挺顺利的,一直到进度跑到大约 37%的时候,就会卡住了,然后和数据库的连接就中断了,试了两三次都是卡在大概同样的进度。起初认为可能是本地网络问题,于是将脚本放到和 ArandoDB 同样的服务器上去跑,结果还是卡在了一样的地方。
于是开始怀疑是不是那一批提交的有点太多了,但是查看了一下发现每一批提交的量也不多,一半就几百个的样子。最后只能试试先全都计算出来,然后再分块提交,这样哪一块出现问题之后只需要重新启动脚本从中断的位置继续提交就好了。
edges_chunks = []
for i in range(0, len(edges), 2000):
edges_chunks.append(edges[i: i + 2000])
for edges_chunk in tqdm(edges_chunks, unit_scale=True):
edges_coll.insert_many(edges_chunk)
令人奇怪的是,尽管占用了巨量的内存,中间也卡主了几次,但没在出现连接中断的情况,并且在花了大约50分钟后终于把这 520万条边给提交上去了。。。
查询
查询就简单多了,首先需要知道“一个顶俩”的文档 id 是多少
for c in chengyu
filter c.word == "一个顶俩"
return c
以及接龙的开始,随便挑选一个成语,例如“遮天映日”
for c in chengyu
filter c.word == "遮天映日"
return c
然后就可以开始寻找最短路径了
for v in OUTBOUND
SHORTEST_PATH "chengyu/41404" to "chengyu/43795" chengyu_edge
return {word: v.word, first: v.first, last: v.last}
查询结果:
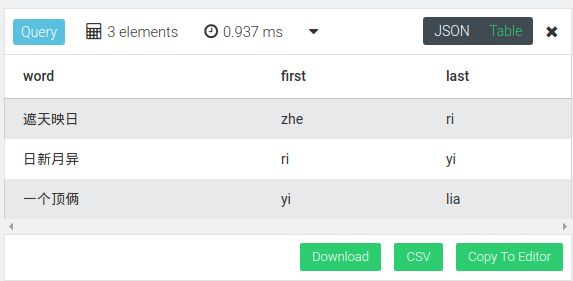
可以看到速度还是很快的.
以及指定最小长度的接龙
for v,e,p in 10 outbound "chengyu/41404" chengyu_edge
filter v._id == "chengyu/43795"
limit 1
return p.vertices
查询结果:
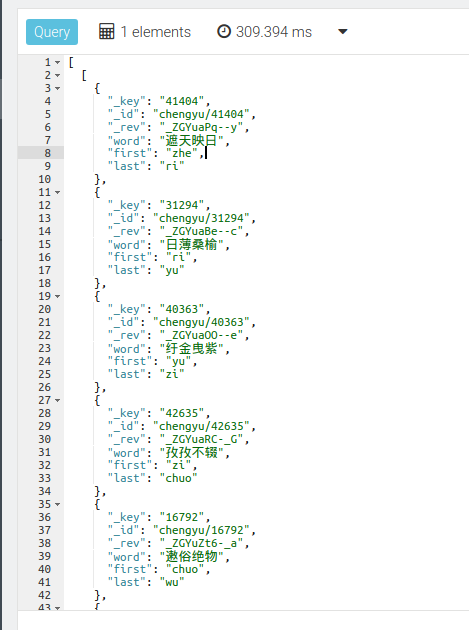
这个返回的结果是双层数组的,试了几种办法都没能做到只靠 AQL 来返回一层数组。。。因为本质上是返回了一条路径里面的顶点。