# 背景
有几个python 代码被使用 PyProtect Angelic47 这个工具加密混淆成 pyc 了, 想要还原回原始代码.
即使是Python自带的dis模块也无法反汇编其代码.
由于经过了混淆, 的确用 dis 也没什么办法, 不过经过了一整天的分析之后, 最终还是成功还原了原来的代码.
知识点
用到的工具集
dis,python自带的字节码工具marshal, 用来读取pyc格式的包uncomplye6, 一个用来反编译pyc到py的工具pycdc, 这也是一个用来反编译pyc的工具, 只不过是用 c++ 写的
分析解密流程
关于 pyc 的格式, 或者执行原理什么的, 就不多说了, 看了上面三篇文章如果还没有理顺的话, 以下的步骤也会很难理解的.
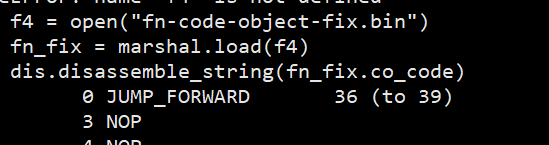
首先我们用 marshal 模块加载经过混淆的 pyc 文件, 前8个字节分别的 magic 和时间戳, 这8个字节需要先跳过.
import dis, marshal
f = open("encrypted.pyc")
f.read(8) # 如果是用的交互式 shell, 此时可以看到前八个字节的具体内容
code = marshal.load(f)
marshal.load 会返回一个 python code object, 这里面就包含了这个 pyc 的全部信息, 我们可以看到类名和文件名等信息都已经被抹去:

不过这没什么关系, 首先查看一下 co_names:

可以看到原本应该是符号名称的集合, 现在已经乱七八糟了, 但是仍然可以看出几个重要的信息, 比如 zlib 和 base64 这两个包, 此时可以盲猜代码需要用 base64 解码, 以及需要用 zlib 进行解压缩的操作.
再检查一下 co_consts 里面有什么:
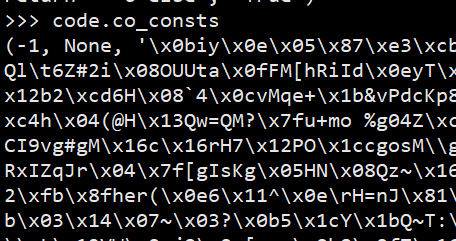
原本应该是常量的地方, 同样有一堆奇怪的东西.
对于这个 code object 来说, 直接使用 dis.disassemble 是不行的, 由于指令都经过混淆, 甚至存在很多假的指令, 这些会让 dis 没有办法完整的反编译出来. 同样的用 disassemble_string 也是没办法反编译出来的.
不过我依然对手上的数个 pyc 使用 disassemble_string 尝试查看里面的部分指令, 有些文件由于插入的指令不一样, 可能第二条指令就没有办法通过而直接报错.
幸好我找到一个文件, disassemble_string 输出了大概 1500 多行的指令, 这些足够我们分析了.
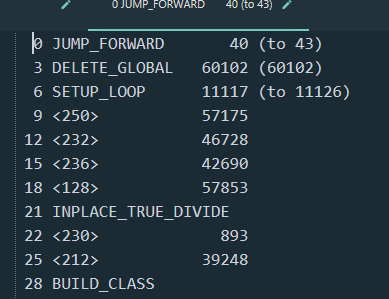
可以看到第一条指令就跳转到了 43 的偏移量上, 之后的操作数都是成千上万这种, 会直接导致 dis 和 uncompyle 等工具的数组越界.
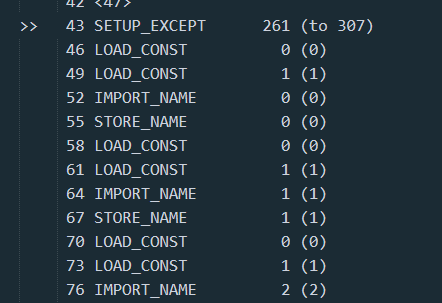
并且, 我足够幸运, 43 偏移量的位置恰好就有一条正确的指令, 而没有因为前面插入的错误指令而让 dis 判断错误, 并漏掉这一条指令.
我们可以看出, 在这里, SETUP_EXPECT 指令创建了一个 try 的环境, 再之后尝试导入了 4 个包, 根据 co_consts 中的信息, 可以判断出这里是分别导入了 sys, zlib, base64, marshal 这四个包, 紧接着调用了 sys._getframe().f_code 获取到了这个 pyc 自身的 code object, 同时赋值给 ^ try elif 这样一个奇怪的变量名字, 不过名字什么的到不重要.
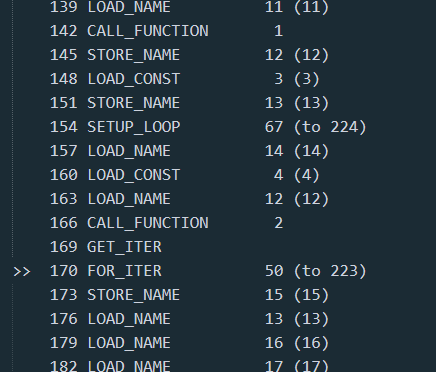
一直到大概 151 行之前, 这些指令码做的操作大概等价于如下伪代码:
var1 = code.co_code # 获取自身的字节码序列
var2 = len(var1)
var3 = code.co_consts[2] # 拿到 consts 里面的第二个元素, 就是之前看到的那个乱码一样的东西
var4 = len(var3)
var5 = ''
在 151 行左右, 初始化了一个空字符串.
154 偏移量的位置, 设置了一个 loop 循环的环境, 这个循环体位于 223 偏移量之前.
根据之前的信息, 这个循环大致等价于:
for idx in range(0, len(consts[2])):
var5 += chr(ord(consts[2][idx]) ^ ord(co_code[idx % len(co_code)]))
也就是用 consts[2] 的内容和 co_code 部分进行异或运算, 并将运算结果累加成一个字符串类型. 不过我们注意到, co_code 的长度是大于 consts 的, 上述的操作只取了 consts 前面的一小部分进行运算, 那么后面的部分总不能都是无意义的垃圾信息吧.
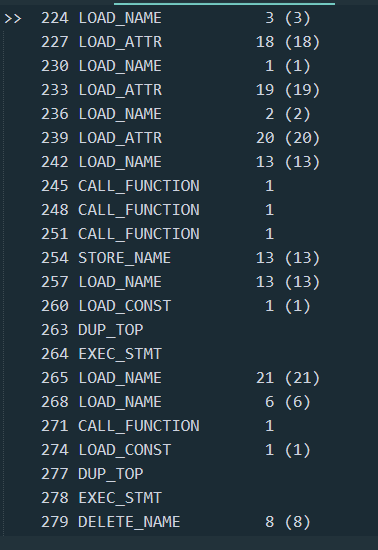
可以看到在循环结束后, 连续进行了三次函数调用, 结合 co_names 的内容, 可以推出这三个函数调用是:
code2 = marshal.loads(zlib.decompress(base64.b64decode(var5)))
果不其然, 是先 base64 解码再解压缩. 执行完这个后, 我们得到了一个新的 code object, 同时我们注意到在 264 偏移处调用了 EXEC_STMT 指令, 以及两个参数, 这条指令的效果就是
exec(code_new, None, None)
但我们不准备执行这个新的 code object ( 其实是我执行过了, 但是并没有对后续分析起到什么推进作用 ).
对这个新的 code object 继续分析组成, 新的 code2 的指令依旧是经过修改的, 仍然不能直接反编译查看.
回到上面那个图, 我们可以看到一共有两个 EXEC_STMT 指令, 第一个指令之前提到了, 这个指令执行完成之后, 265, 268, 271 这三条指令, 是一次函数调用, 并且被调用者有一个参数, 而这个参数, 就是我们之前看到的 sys._getframe().f_code 所拿到的 pyc 自身的 code object.
而这个函数名, 可以在原来的 code object 中的 co_names 中通过 21 索引查看到, 我这里是一个 ^ return - 6 else 这样的字符串. 乍一看还真的不能让人认为是一个函数名字啊.
而这个 ^ return - 6 else 同样出现在 code2 的 co_names 中, 因此大胆推测 code2 的执行效果就是创建一个函数, 并且把自身 pyc 的 code object 传进去, 再进行进一步的操作.
这个新的 code2 虽然说不能被反编译, 但是我们看到他的 co_consts 里面, 有个叫做 pyopencoder_opDecoder 的对象, 这是我们首次发现的名字没有经过混淆的 code object, 尝试对这个 pyopencoder_opDecoder 进行反编译:
uncompyle6.main.decompile(2.7, code2.co_consts[2], sys.stdout)
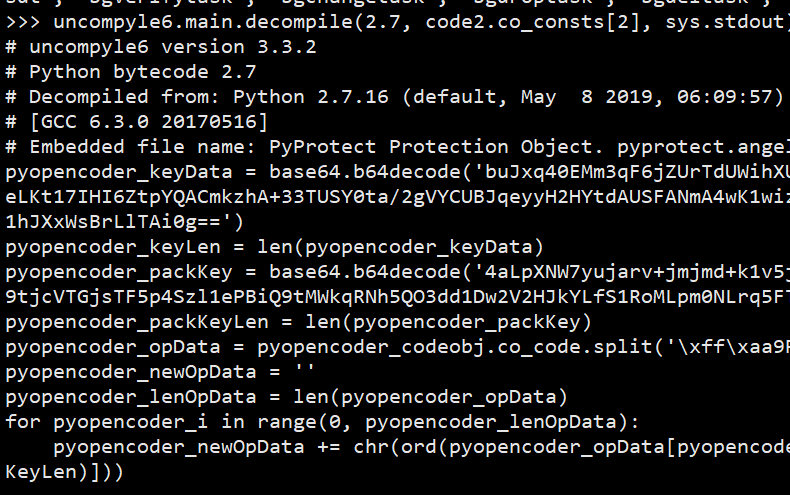
好的, 我们成功的看到了这个函数体的庐山真面目, 这个函数依旧很复杂, 不过我们不需要看他是做什么的, 不过其中有两个 for 循环, 这个循环和我们一开始推出来的解码方式是一样的, 都是同样的异或运算操作.
但是这个 code object 并不能调用怎么办, 我们需要将这个 code object 转换成一个函数来供我们调用. 借助于 python 的强大功能:
from types import FunctionType
opdecoder = FunctionType(code2.co_consts[2], globals())
code3 = opdecoder(code)
通过 FunctionType 我们可以从一个 code object 来创建出一个函数对象, 接着我们调用这个函数, 并把 pyc 原始的 code object 作为参数传入, 可以得到第三个 code object, 而这个 code object 除了指令码依然是插花的之外, 已经可以看到函数名之类的信息了.
最后处理插花
code3 的 co_consts 里面就可以看到这个 pyc 里面的所有信息了, 包括函数, 类定义之类的都有.
但是这些依旧不能直接反编译. 使用 dis 查看他们的字节码可以发现. 依旧是在开头有同样的手段进行了插花, 不过这些处理起来也很简单, 我们只需要查看第一条指令跳转到哪里.
比如:
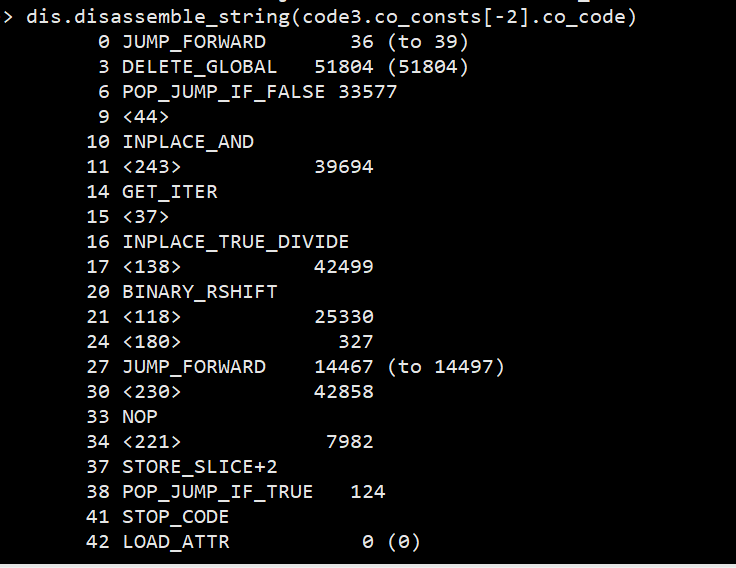
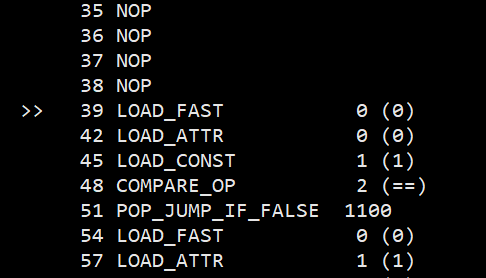
可以看到, 第一条指令直接跳转到了偏移量39的位置, 然而并没有发现偏移量为 39 的指令, 这说明 dis 出现了偏差. 我们需要做的就是, 将第4个字节开始, 一直到第 39 字节之前的部分, 全部都替换填充成 09 号 NOP 指令, 这是一个占位符指令, 他并不会有任何作用, 同时他是一个无参数指令, 因此占用空间就只有一个字节.
我选择先用 marshal 将这个函数序列化成一个二进制文件, 然后用 16 进制编辑器, 完成上述的替换步骤.


在图上, 高亮出的部分就是第一条 JUMP_FORWARD 指令, 占用三字节, 第三字节固定为 0x00.
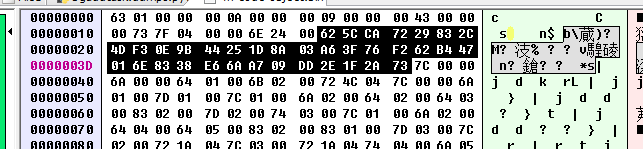
现在高亮的部分就是需要清理的部分, 全部都替换成09. 之后再次用 marshal 加载.
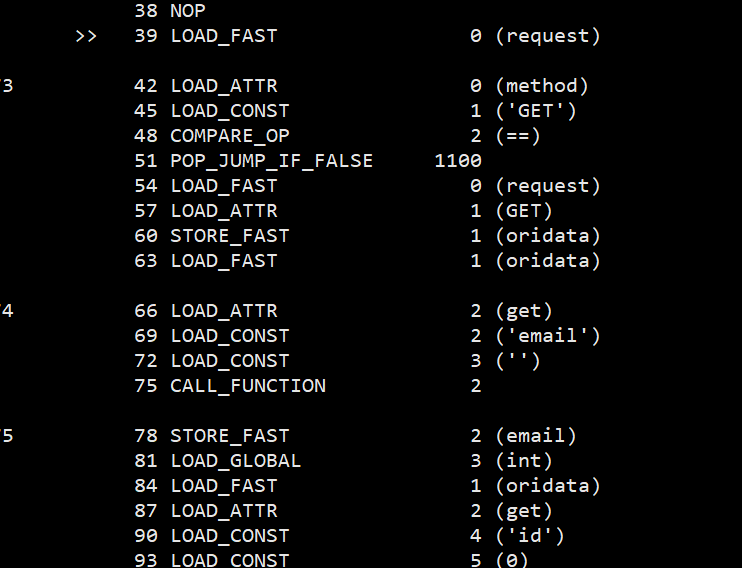
可以看到这里已经没什么问题了. 不过这段代码用 uncompyle 依旧是没办法处理的… 会因为一些 None 的地方而报错, 暂时不太清楚为什么, 推测可能缺少一些上一层, 也就是 code3 部分的东西.
但是现在处理过后的这段 code object 是可以使用 dis.disassemble 来正常处理的, 可以把各种常量等符号都显示出来, 对于一些逻辑简单的代码来说, 光靠这部分字节码序列就已经足够手动还原成原来的代码了.
结尾
尽管我们成功的解出了原始的字节码, 不过这中间有不少手动操作, 这些其实都是可以通过脚本去自动化的去处理的, 之后有空再写自动处理的吧.
非常荣幸您能有兴趣研究我的小项目~
这里的这个PyProtect起初是我的一个测试版小工具,出于兴趣爱好开发.
其实正如您所说,我在混淆的时候丢失了一个很关键的步骤,即混淆第二部分的code object. 这里非常失误,严重暴露了第二步的解密算法. 非常感谢您的这个提醒~
多说一点,至于后面的opcode插花,其实我也有写过类似的反向还原工具,基本原理是外部虚拟机模拟python栈机,对所有运行流中存在的常量进行计算,找到所有的横成立跳转,最终标记出所有不可能执行到的代码,从而进行代码清理.
这招之前在处理某游戏公司被混淆(混淆工具可能是私有工具)的pyc中显示出了相当棒的效果,很大一部分逻辑被全自动处理后由于没有了花指令,可以直接送入uncompyle6. 但对于同一个分支的opcode顺序(比如if和elif)被打乱的情况下,这个工具依然无能为力.
当然,因为PyProtect初代版本仅仅是一些混淆算法,加之这是第一个公开的有些针对性的基于操作码混淆的Python保护工具,大家所有人都对此有非常高的兴趣. 在多方的共同研究下,显然它的强度有些不够. 针对此,我也开发了PyProtect2.0版本.
此版本加密强度和PyProtect初代版本完全不同,PyProtect2.0在初代版本上增加了更多可选选项,比如代码顺序完全打乱、随机插花、虚拟机保护(AVM Protect)等很多高级保护功能,将在近一个月内正式上线.
我非常欢迎您能有兴趣继续研究我的PyProtect2.0版本,也非常欢迎您来和我讨论各种Python(或者不止局限于Python)的运行原理和特殊运用思路等.
当PyProtect2.0上线后,如您需要,我将不收您任何费用,您可随便使用、研究其中的任何技术思路.
当然,在import this的时候,我们是知道其实Python的美学在于代码开放、简洁于灵活,而不是代码混淆. 我也是开源软件的爱好者和贡献者,也更希望您和您现在一样,持续保持一份研究的热情,也更希望您继续保持一份对开源开放的初心.
最后,我要说的是,PyProtect项目对来自所有人的研究都抱着欢迎和荣幸的态度,希望任何人不要感觉到有什么压力. 因为对此我并没有任何想追究版权或要求删除的意思,任何技术本身是自由的.